强化学习¶
安装大小
强化学习依赖项包含 torch 等大型软件包,在运行 ./setup.sh -i 时需通过回答 "y" 来明确请求(当询问"是否同时安装 freqai-rl 的依赖项(约需额外 700MB 空间)[y/N]?"时)。
偏好使用 docker 的用户应确保使用带有 _freqairl 后缀的 docker 镜像。
背景与术语¶
什么是强化学习?FreqAI 为何需要它?¶
强化学习包含两个重要组成部分:智能体和训练环境。在智能体训练过程中,智能体会逐根K线遍历历史数据,始终从一组动作中做出选择:多头开仓、多头平仓、空头开仓、空头平仓、中性)。在此训练过程中,环境会跟踪这些动作的表现,并根据用户自定义的 calculate_reward() 函数(我们在此提供了默认奖励函数供用户在此基础上构建详见此处)给予智能体奖励。该奖励用于训练神经网络中的权重。
FreqAI 强化学习实现的第二个重要组成部分是状态信息的使用。状态信息在每一步都会输入网络,包括当前利润、当前持仓和当前交易持续时间。这些信息用于在训练环境中训练智能体,并在模拟/实盘交易中强化智能体(此功能在回测中不可用)。FreqAI + Freqtrade 是这种强化机制的完美匹配,因为在实盘部署中这些信息是现成可用的。
强化学习是 FreqAI 的自然演进,因为它增加了一层新的自适应性和市场反应能力,这是分类器和回归器无法比拟的。然而,分类器和回归器具有 RL 所没有的优势,例如稳健的预测能力。训练不当的 RL 智能体可能会找到"作弊"和"取巧"的方法来最大化奖励,而实际上并未赢得任何交易。因此,RL 比典型的分类器和回归器更复杂,需要更高层次的理解。
RL 接口¶
在当前框架下,我们旨在通过通用的"预测模型"文件暴露训练环境,该文件是用户继承的 BaseReinforcementLearner 对象(例如 freqai/prediction_models/ReinforcementLearner)。在此用户类内部,RL 环境可通过 MyRLEnv 进行可用性和自定义,如下文所示。
我们设想大多数用户将主要精力放在 calculate_reward() 函数的创意设计上详见此处,而保持环境的其余部分不变。其他用户可能完全不会修改环境,他们只会调整配置设置并利用 FreqAI 中已有的强大特征工程功能。同时,我们也支持高级用户完全创建自己的模型类。
该框架基于 stable_baselines3(torch)和 OpenAI gym 的基础环境类构建。但总体而言,模型类是高度隔离的。因此,可以轻松将竞争性库集成到现有框架中。对于环境类,它继承自 gym.Env,这意味着若要切换到不同的库,必须编写一个全新的环境。
重要注意事项¶
如上所述,智能体是在人工交易"环境"中进行"训练"的。在我们的案例中,该环境可能看起来与真实的 Freqtrade 回测环境非常相似,但实则并非如此。实际上,强化学习训练环境要简化得多。它不包含任何复杂的策略逻辑,例如 custom_exit、custom_stoploss、杠杆控制等回调函数。相反,强化学习环境是对真实市场的非常"原始"的表示,智能体在其中可以自由学习由 calculate_reward() 强制执行的政策(即:止损、止盈等)。因此,必须认识到智能体训练环境与现实世界并不相同。
运行强化学习¶
设置和运行强化学习模型与运行回归器或分类器相同。必须在命令行上定义相同的两个标志 --freqaimodel 和 --strategy:
freqtrade trade --freqaimodel ReinforcementLearner --strategy MyRLStrategy --config config.json
其中 ReinforcementLearner 将使用来自 freqai/prediction_models/ReinforcementLearner 的模板化 ReinforcementLearner(或位于 user_data/freqaimodels 的用户自定义模型)。而策略则遵循与典型回归器相同的特征工程基础,使用 feature_engineering_*。不同之处在于目标的创建,强化学习不需要目标。但 FreqAI 要求在动作列中设置一个默认(中性)值:
def set_freqai_targets(self, dataframe, **kwargs) -> DataFrame:
"""
*Only functional with FreqAI enabled strategies*
Required function to set the targets for the model.
All targets must be prepended with `&` to be recognized by the FreqAI internals.
More details about feature engineering available:
https://www.freqtrade.io/en/latest/freqai-feature-engineering
:param df: strategy dataframe which will receive the targets
usage example: dataframe["&-target"] = dataframe["close"].shift(-1) / dataframe["close"]
"""
# For RL, there are no direct targets to set. This is filler (neutral)
# until the agent sends an action.
dataframe["&-action"] = 0
return dataframe
大部分功能与典型回归器保持一致,但以下函数展示了策略如何必须将原始价格数据传递给智能体,以便其在训练环境中能够访问原始 OHLCV 数据:
def feature_engineering_standard(self, dataframe: DataFrame, **kwargs) -> DataFrame:
# The following features are necessary for RL models
dataframe[f"%-raw_close"] = dataframe["close"]
dataframe[f"%-raw_open"] = dataframe["open"]
dataframe[f"%-raw_high"] = dataframe["high"]
dataframe[f"%-raw_low"] = dataframe["low"]
return dataframe
最后,这里没有明确的“标签”需要制作——而是需要分配 &-action 列,该列在 populate_entry/exit_trends() 中访问时将包含智能体的动作。在当前示例中,中性动作为 0。该值应与所使用的环境保持一致。FreqAI 提供两种环境,均使用 0 作为中性动作。
当用户意识到无需设置标签后,很快就会理解智能体正在做出“自己的”入场和出场决策。这使得策略构建相当简单。入场和出场信号以整数形式来自智能体——这些整数直接用于在策略中决定入场和出场:
def populate_entry_trend(self, df: DataFrame, metadata: dict) -> DataFrame:
enter_long_conditions = [df["do_predict"] == 1, df["&-action"] == 1]
if enter_long_conditions:
df.loc[
reduce(lambda x, y: x & y, enter_long_conditions), ["enter_long", "enter_tag"]
] = (1, "long")
enter_short_conditions = [df["do_predict"] == 1, df["&-action"] == 3]
if enter_short_conditions:
df.loc[
reduce(lambda x, y: x & y, enter_short_conditions), ["enter_short", "enter_tag"]
] = (1, "short")
return df
def populate_exit_trend(self, df: DataFrame, metadata: dict) -> DataFrame:
exit_long_conditions = [df["do_predict"] == 1, df["&-action"] == 2]
if exit_long_conditions:
df.loc[reduce(lambda x, y: x & y, exit_long_conditions), "exit_long"] = 1
exit_short_conditions = [df["do_predict"] == 1, df["&-action"] == 4]
if exit_short_conditions:
df.loc[reduce(lambda x, y: x & y, exit_short_conditions), "exit_short"] = 1
return df
需要重点考虑的是,&-action 的具体含义取决于用户选择使用的环境。以上示例展示了5种动作类型,其中0代表中性,1代表开多仓,2代表平多仓,3代表开空仓,4代表平空仓。
配置强化学习器¶
要配置 Reinforcement Learner,必须在 freqai 配置中包含以下字典:
"rl_config": {
"train_cycles": 25,
"add_state_info": true,
"max_trade_duration_candles": 300,
"max_training_drawdown_pct": 0.02,
"cpu_count": 8,
"model_type": "PPO",
"policy_type": "MlpPolicy",
"model_reward_parameters": {
"rr": 1,
"profit_aim": 0.025
}
}
参数详情可查阅参数表。总体而言,train_cycles 决定了智能体应在其模拟环境中遍历蜡烛数据的次数以训练模型权重。model_type 是一个字符串参数,用于选择 stable_baselines(外部链接)中提供的可用模型之一。
Note
若希望尝试 continual_learning 功能,需在主 freqai 配置字典中将该参数设为 true。这将指示强化学习库从先前模型的最终状态继续训练新模型,而非在每次重新训练时从头开始训练新模型。
Note
请注意,通用的 model_training_parameters 字典应包含特定 model_type 所需的所有模型超参数定制项。例如,PPO 算法的参数可在此文档中查看。
创建自定义奖励函数¶
Not for production
警告! Freqtrade 源代码附带的奖励函数是一个功能展示,旨在演示/测试尽可能多的环境控制特性。它也被设计为在小型计算机上快速运行。这是一个基准测试,不适用于实际生产环境。请注意,您需要创建自己的 custom_reward() 函数,或使用 Freqtrade 源代码之外由其他用户构建的模板。
当你开始修改策略和预测模型时,你会很快意识到强化学习器与回归器/分类器之间的一些重要区别。首先,策略不设置目标值(没有标签!)。相反,你在 MyRLEnv 类中设置 calculate_reward() 函数(见下文)。prediction_models/ReinforcementLearner.py 中提供了一个默认的 calculate_reward() 来演示创建奖励的必要构建模块,但这并非为生产环境设计。用户必须创建自己的自定义强化学习模型类,或使用 Freqtrade 源代码外部的预构建模型,并将其保存到 user_data/freqaimodels。正是在 calculate_reward() 函数中,可以表达关于市场的创造性理论。例如,当智能体进行盈利交易时你可以给予奖励,而当智能体进行亏损交易时则进行惩罚。或者,你可能希望奖励智能体进入交易,并惩罚智能体持仓时间过长。下面我们展示这些奖励是如何计算的示例:
提示
最佳的奖励函数是那些连续可微且缩放良好的函数。换句话说,对罕见事件施加单一的大额负惩罚并非良策,神经网络将无法学习该函数。相反,对常见事件施加小额负惩罚更为可取,这将有助于智能体更快地学习。不仅如此,你还可以通过让奖励/惩罚根据某些线性/指数函数按严重程度缩放,来提升其连续性。例如,随着交易持续时间的增加逐步放大惩罚,这比在单一时间点施加一次性大额惩罚更为有效。
from freqtrade.freqai.prediction_models.ReinforcementLearner import ReinforcementLearner
from freqtrade.freqai.RL.Base5ActionRLEnv import Actions, Base5ActionRLEnv, Positions
class MyCoolRLModel(ReinforcementLearner):
"""
User created RL prediction model.
Save this file to `freqtrade/user_data/freqaimodels`
then use it with:
freqtrade trade --freqaimodel MyCoolRLModel --config config.json --strategy SomeCoolStrat
Here the users can override any of the functions
available in the `IFreqaiModel` inheritance tree. Most importantly for RL, this
is where the user overrides `MyRLEnv` (see below), to define custom
`calculate_reward()` function, or to override any other parts of the environment.
This class also allows users to override any other part of the IFreqaiModel tree.
For example, the user can override `def fit()` or `def train()` or `def predict()`
to take fine-tuned control over these processes.
Another common override may be `def data_cleaning_predict()` where the user can
take fine-tuned control over the data handling pipeline.
"""
class MyRLEnv(Base5ActionRLEnv):
"""
User made custom environment. This class inherits from BaseEnvironment and gym.Env.
Users can override any functions from those parent classes. Here is an example
of a user customized `calculate_reward()` function.
Warning!
This is function is a showcase of functionality designed to show as many possible
environment control features as possible. It is also designed to run quickly
on small computers. This is a benchmark, it is *not* for live production.
"""
def calculate_reward(self, action: int) -> float:
# first, penalize if the action is not valid
if not self._is_valid(action):
return -2
pnl = self.get_unrealized_profit()
factor = 100
pair = self.pair.replace(':', '')
# you can use feature values from dataframe
# Assumes the shifted RSI indicator has been generated in the strategy.
rsi_now = self.raw_features[f"%-rsi-period_10_shift-1_{pair}_"
f"{self.config['timeframe']}"].iloc[self._current_tick]
# reward agent for entering trades
if (action in (Actions.Long_enter.value, Actions.Short_enter.value)
and self._position == Positions.Neutral):
if rsi_now < 40:
factor = 40 / rsi_now
else:
factor = 1
return 25 * factor
# discourage agent from not entering trades
if action == Actions.Neutral.value and self._position == Positions.Neutral:
return -1
max_trade_duration = self.rl_config.get('max_trade_duration_candles', 300)
trade_duration = self._current_tick - self._last_trade_tick
if trade_duration <= max_trade_duration:
factor *= 1.5
elif trade_duration > max_trade_duration:
factor *= 0.5
# discourage sitting in position
if self._position in (Positions.Short, Positions.Long) and \
action == Actions.Neutral.value:
return -1 * trade_duration / max_trade_duration
# close long
if action == Actions.Long_exit.value and self._position == Positions.Long:
if pnl > self.profit_aim * self.rr:
factor *= self.rl_config['model_reward_parameters'].get('win_reward_factor', 2)
return float(pnl * factor)
# close short
if action == Actions.Short_exit.value and self._position == Positions.Short:
if pnl > self.profit_aim * self.rr:
factor *= self.rl_config['model_reward_parameters'].get('win_reward_factor', 2)
return float(pnl * factor)
return 0.
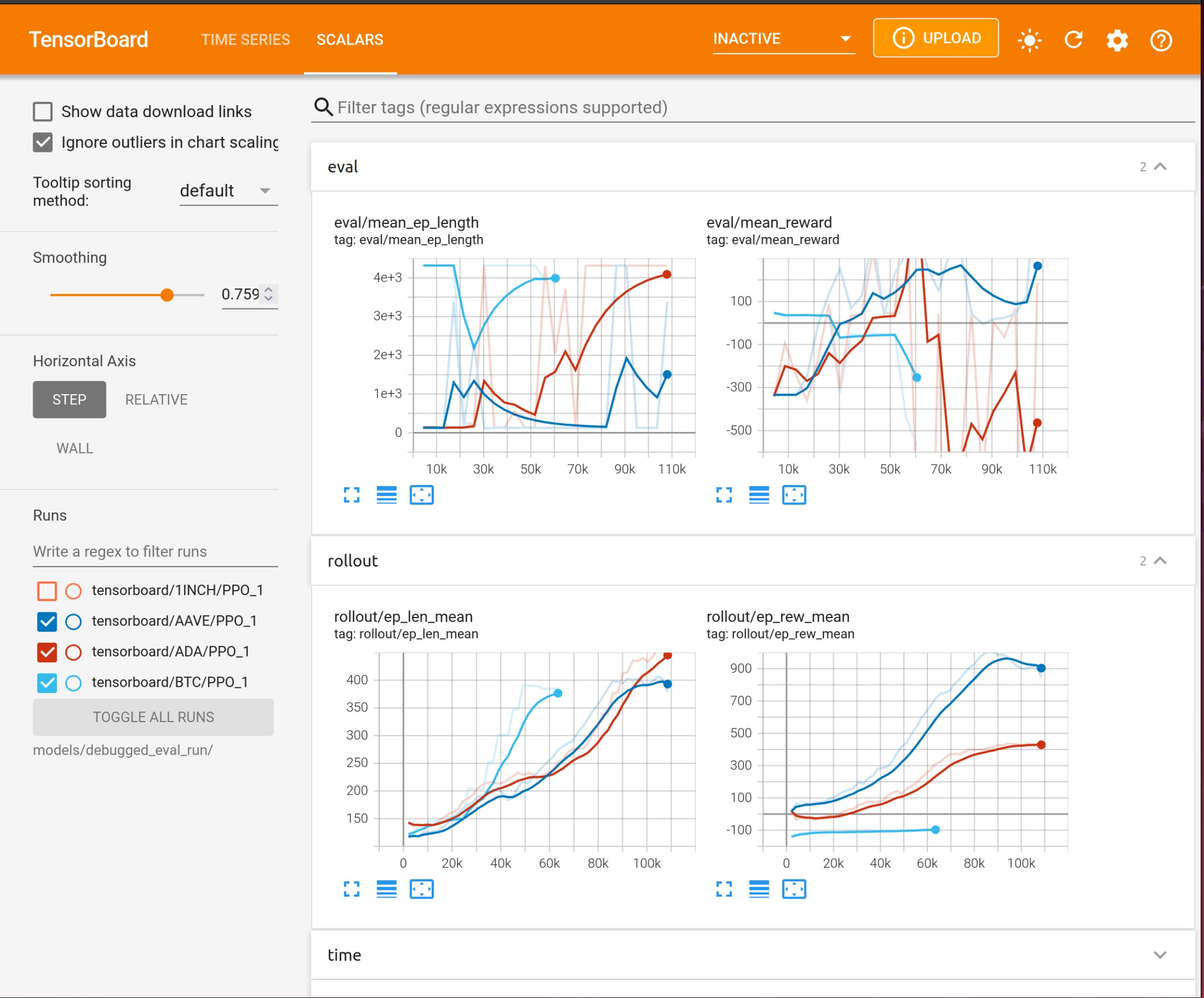
使用 Tensorboard¶
强化学习模型受益于训练指标的追踪。FreqAI 集成了 Tensorboard,允许用户跨所有币种和所有重新训练周期追踪训练和评估表现。通过以下命令激活 Tensorboard:
tensorboard --logdir user_data/models/unique-id
其中 unique-id 为 freqai 配置文件中设置的 identifier。该命令需在独立终端中运行,方可在浏览器中通过 127.0.0.1:6006(6006 为 Tensorboard 默认端口)查看输出。
自定义日志记录¶
FreqAI 还提供了一个内置的回合总结记录器 self.tensorboard_log,用于向 Tensorboard 日志添加自定义信息。默认情况下,该函数在环境中每步调用一次以记录智能体动作。单个回合中所有步骤累积的所有值会在每个回合结束时报告,随后将所有指标完全重置为 0,为后续回合做准备。
self.tensorboard_log 也可在环境中的任何位置使用,例如,可以将其添加到 calculate_reward 函数中,以收集有关奖励各个部分被调用频率的更详细信息:
class MyRLEnv(Base5ActionRLEnv):
"""
User made custom environment. This class inherits from BaseEnvironment and gym.Env.
Users can override any functions from those parent classes. Here is an example
of a user customized `calculate_reward()` function.
"""
def calculate_reward(self, action: int) -> float:
if not self._is_valid(action):
self.tensorboard_log("invalid")
return -2
Note
self.tensorboard_log() 函数专为跟踪增量对象而设计,即训练环境中的事件、动作。如果关注的事件是浮点数,则可将浮点数作为第二个参数传递,例如 self.tensorboard_log("float_metric1", 0.23)。此种情况下,指标值不会递增。
选择基础环境¶
FreqAI 提供了三种基础环境:Base3ActionRLEnvironment、Base4ActionEnvironment 和 Base5ActionEnvironment。顾名思义,这些环境分别针对可选择 3、4 或 5 种动作的智能体进行定制。Base3ActionEnvironment 是最简单的环境,智能体可选择持有、做多或做空。该环境也可用于仅做多机器人(它会自动遵循策略中的 can_short 标志),其中做多为入场条件,做空为离场条件。而在 Base4ActionEnvironment 中,智能体可选择做多入场、做空入场、保持中性或平仓离场。最后,在 Base5ActionEnvironment 中,智能体具有与 Base4 相同的动作,但不同于单一离场动作,它会区分平多仓和平空仓。环境选择带来的主要变化包括:
calculate_reward中可用的动作- 用户策略所消耗的动作
FreqAI 提供的所有环境都继承自一个与操作/仓位无关的环境对象,称为 BaseEnvironment,其中包含了所有共享逻辑。该架构设计为易于定制。最简单的定制是 calculate_reward()(详见此处)。然而,定制可以进一步扩展到环境中的任何函数。您只需在预测模型文件的 MyRLEnv 中重写这些函数即可实现。对于更高级的定制,建议创建一个从 BaseEnvironment 继承的全新环境。
Note
只有 Base3ActionRLEnv 可以进行仅做多训练/交易(将用户策略属性设置为 can_short = False)。